This is the 2nd launch from Gemini 2.5 Flash. View more
Gemini 2.5 Flash-Lite
Google's fastest, most cost-efficient model
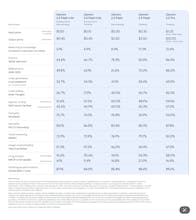
Gemini 2.5 Flash-Lite is Google's new, fastest, and most cost-efficient model in the 2.5 family. It offers higher quality and lower latency than previous Lite versions while still supporting a 1M token context window and tool use. Now in preview.
Hi everyone!
The Gemini 2.5 model family is now officially generally available, which is great news, even though many of us have been following the frequent iterations and using the preview versions for a while now.
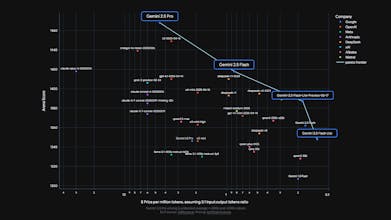
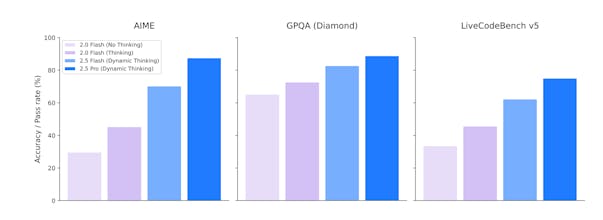
But the brand new model here is Gemini 2.5 Flash-Lite. It's lightweight enough, fast enough, and most importantly, cost-efficient enough – while still being remarkably smart. It has a higher quality than previous Flash-Lite versions but with even lower latency. That's a fantastic combination.
For those high-volume, latency-sensitive tasks like classification or translation, having a model this fast that still supports a 1M token context and tool use is a very powerful new option.
Impressive to see Google optimizing not just for intelligence but also for speed and cost. Does Gemini 2.5 Flash-Lite offer any fine-tuning or custom instruction capabilities for enterprise-level workflows?
We used Gemini to generate structured notes and power Auralix's voice tutor. It's fast, efficient, and gives us control over both content and how it's delivered.















Impressive to see Google optimizing not just for intelligence but also for speed and cost. Does Gemini 2.5 Flash-Lite offer any fine-tuning or custom instruction capabilities for enterprise-level workflows?
All the best for the launch @sundar_pichai & team!